On Integration: Organizing the data
In my last post on using the database for integration, I argued that the best metaphor for creating systems that are interconnected is that of One-Large Database. Carl-Henrik asked some very relevant questions about this, which I will interpret (for now) mainly as “how do you avoid drowning in complexity”. This post will address the issue of maintainability, especially when things grow to be large.
The On Large Database metaphor is mostly useful as a starting point. The first thing I notice when I look at our systems that have been organized this way is the fact that the data-structure is far from flat. Each application will deal with four categories of tables. First, an application has a large private domain, containing tables that the rest of the world has no business messing with. Second, it exports some tables that other applications use. Third, it imports tables exported by other applications. And finally, there are some tables that are shared by a number of applications with no clear owner. The last case is something we normally want to avoid.
In my experience, the integration scenarios can further be divided into four cases: Reference data, Consolidated data, Published data, and Subscription data.
Perhaps the most useful of the integration scenarios is that of Reference Data. Reference Data is exported by an application that is responsible for maintaining the data. Applications import Reference Data read-only. Reference data is very common in all domains. It often contains customer databases and other core data entities. 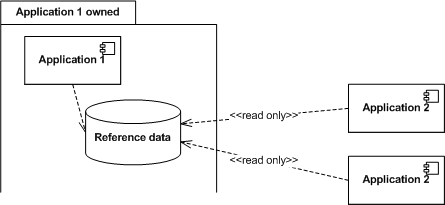 In some special cases, you might want shared data to be updated by a distributed set of applications. I call this scenario Consolidated View. One application is responsible for displaying a shared view of data that is being maintained by a number of applications. Each application will normally be responsible for reading and updating a subset of the shared data. This scenario is not as common as Reference data, but we see it for example in a situation where we want a consolidated view of all the contracts a particular customer (which is in the Reference data domain) holds. The different contracts are defined in the applications that operate on them (for example, a contract for a payment service is defined in the payment service system). A consolidated view allows us to display all the contracts a customer holds, even though the details are distributed in a number of applications.
In some special cases, you might want shared data to be updated by a distributed set of applications. I call this scenario Consolidated View. One application is responsible for displaying a shared view of data that is being maintained by a number of applications. Each application will normally be responsible for reading and updating a subset of the shared data. This scenario is not as common as Reference data, but we see it for example in a situation where we want a consolidated view of all the contracts a particular customer (which is in the Reference data domain) holds. The different contracts are defined in the applications that operate on them (for example, a contract for a payment service is defined in the payment service system). A consolidated view allows us to display all the contracts a customer holds, even though the details are distributed in a number of applications. 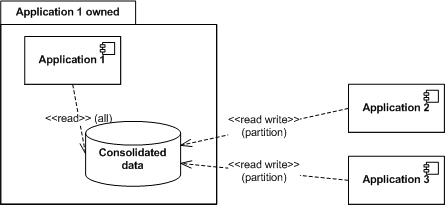 These two scenarios are the ones used for sharing data. The last two scenarios are used to delegate responsibility. I call them Publishing and Subscription domains, respectively. Essentially, the subscribing party in these scenarios will poll the database at an appropriate interval. A little or a lot of sophistication can be put into the polling implementation as desired. Publishing domains distribute data from one application to many. The domain is exported by the publishing application. Each subscribing application is usually responsible for a partition of the data. They will remove or update this data as they consume it. The most common example is an application that receives files that should be processed by one of many applications, depending on the type of file.
These two scenarios are the ones used for sharing data. The last two scenarios are used to delegate responsibility. I call them Publishing and Subscription domains, respectively. Essentially, the subscribing party in these scenarios will poll the database at an appropriate interval. A little or a lot of sophistication can be put into the polling implementation as desired. Publishing domains distribute data from one application to many. The domain is exported by the publishing application. Each subscribing application is usually responsible for a partition of the data. They will remove or update this data as they consume it. The most common example is an application that receives files that should be processed by one of many applications, depending on the type of file. 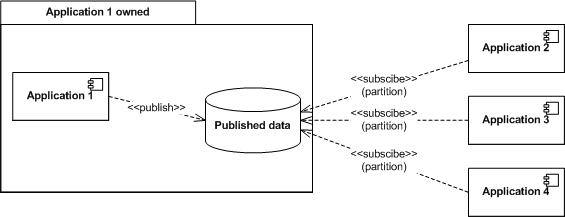 Subscription domains collect data from many applications into one. The domain is exported by the subscribing application, which also may remove and update data. The publishing applications insert data into the subscription domain. The most common example of subscription domain is an application collecting events for distribution or for billing.
Subscription domains collect data from many applications into one. The domain is exported by the subscribing application, which also may remove and update data. The publishing applications insert data into the subscription domain. The most common example of subscription domain is an application collecting events for distribution or for billing. 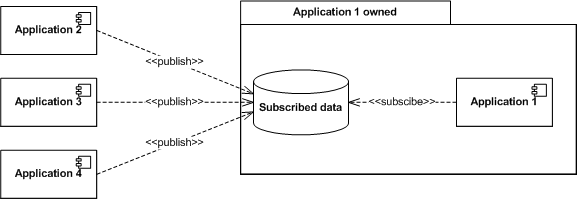 Notably absent from the list is the one-to-many event publishing scenario. All the publish-subscribe scenarios I have talked about are point-to-point, not broadcasts. This is by design. All the examples we have seen so far have been broadcasting changes to a Reference domain. So far, it seems like these scenarios are better served by having a tighter integration with the Reference domain. I am still looking for counter examples. In each of the four scenarios I have listed (Reference Data, Consolidated View, Publishing, Subscription) there is a clear definition of who is the client and who is the server. There is also a clear definition of which operations should be allowed by each party. For example, in the Consolidated View, the clients should be able to Created, Update and Delete data in their segment of the domain, and the server should only Read data. We currently implement these restrictions as GRANTS in the database. In most domain, the manageability can be improved by simplifying the exported domains. This can be implemented by using VIEWS. VIEWS will also allow the server to change the internal structure without breaking clients, and allow clients that need different versions of the exported domain to coexist. It is important to note that for an application, it is transparent whether it is accessing a TABLE or a VIEW. This means that we can at a later time replace tables with views. I might write more on views in a later post. I hope this post explains how to make the Single Database vision Manageable. Seen from one application, we will still maintain the illusion that it has direct access to all data. By using SYNONYMS, we can make the logical division into imported and exported domains transparent. This means that the application will be deployed in a single database schema in development and test environments, and the full glory of the integrating applications will only be revealed when we put the application into integration tests or production environments. The fact that we have defined a limited number of integration scenarios mean that we can analyze how to make each scale separately. Stay tuned for my next post, where I discuss how to make the Single Database Vision scale to scenarios where different applications have to use different database instances.
Notably absent from the list is the one-to-many event publishing scenario. All the publish-subscribe scenarios I have talked about are point-to-point, not broadcasts. This is by design. All the examples we have seen so far have been broadcasting changes to a Reference domain. So far, it seems like these scenarios are better served by having a tighter integration with the Reference domain. I am still looking for counter examples. In each of the four scenarios I have listed (Reference Data, Consolidated View, Publishing, Subscription) there is a clear definition of who is the client and who is the server. There is also a clear definition of which operations should be allowed by each party. For example, in the Consolidated View, the clients should be able to Created, Update and Delete data in their segment of the domain, and the server should only Read data. We currently implement these restrictions as GRANTS in the database. In most domain, the manageability can be improved by simplifying the exported domains. This can be implemented by using VIEWS. VIEWS will also allow the server to change the internal structure without breaking clients, and allow clients that need different versions of the exported domain to coexist. It is important to note that for an application, it is transparent whether it is accessing a TABLE or a VIEW. This means that we can at a later time replace tables with views. I might write more on views in a later post. I hope this post explains how to make the Single Database vision Manageable. Seen from one application, we will still maintain the illusion that it has direct access to all data. By using SYNONYMS, we can make the logical division into imported and exported domains transparent. This means that the application will be deployed in a single database schema in development and test environments, and the full glory of the integrating applications will only be revealed when we put the application into integration tests or production environments. The fact that we have defined a limited number of integration scenarios mean that we can analyze how to make each scale separately. Stay tuned for my next post, where I discuss how to make the Single Database Vision scale to scenarios where different applications have to use different database instances.